自己紹介
こんにちは。今年の7月からリクルートマーケティングパートナーズに入社した木村 勇太です。
私は現在開発支援G 1)エンジニアをサポートするエンジニア~RMP内製開発の強さ・魅力~ という。インフラや自動化など内製エンジニアへの開発支援を行うグループに属しています。
はじめに
弊社サービスの スタディサプリ ENGLISH ではアーキテクチャにMicroservices、gRPCを利用してサーバーサイドを構築しています。スタディサプリ ENGLISH のMicroservices化についての詳細は以下の記事にてご紹介しています。
今回、gRPCの負荷分散にEnvoyとAmazon ECS Service Discoveryを利用した構成を導入したので紹介します。
gRPCとは?

gRPCとはGoogleが開発・運用をしているRPCの(Remote Procedure Call)のfremeworkです。Protocol Buffersを利用したIDLのインターフェイスの統一とシリアライズ、通信はHTTP/2を利用していて、その高速性や統一性によって採用事例が増えているプロダクトです。
AWSのELBのHTTP/2の対応状況
スタディサプリ ENGLISH ではインフラにAWSを利用しています。
gRPCはHTTP/2を利用しているので、負荷分散を適切に行うためにはHTTP/2を扱える必要があります。ですが、現時点(2018年10月)でAWSではHTTP/2に完全対応しているELBはありません2)Will ALB (or ELB) support HTTP/2 anytime?。
ALB update
- 2020/11/2 に ALBでend to endでのhttp2とgprcの対応が発表されました!この記事の内容を使わなくても、gRPCを取り扱えるようになりました!
CLB (Classic Load Balancer)
HTTP/2未対応
ALB (Application Load Balancer)
HTTPS リスナー側はHTTP/2対応しているが、内部通信はHTTP/2に対応していない。
NLB (Network Load Balancer)
L4レベルのロードバランサーなので、L7のHTTP/2に個別対応出来ない。
当初の状態・問題点
CLBのTCPリスナーの機能を使って、HTTP/2のL7ではなく、L4レイヤーでのバランシングを行っていました。 ですが、DatadogでサービスのMetricsを確認してみると、一部のContainerに負荷が寄っている現状が散見され、時には障害が発生する状態でした。
原因
HTTP/2を扱うgRPCでは一つのconnectionを保持し続ける形で複数のrequestを処理します。L4レイヤーでバランシングを行ってしまうと、connectionが切断されない限り同じサーバーへとrequestが送られ続けます。運が良くサーバーにconnectionが回れば良いですが、運が悪いと同じサーバーにrequestが送られ続ける→結果負荷が偏るということが発生していることが判明しました。
gRPCの負荷分散
このままでは問題があると感じたので、gRPCに関しての負荷分散について調べました。公式に負荷分散についてのページがあるので非常に参考になりました3)gRPC Load Balancing。
gRPCの負荷分散には大きく分けて2つの方式があります(厳密には3つの方法が提示されているが、実装例がほとんど無い)
Proxy load balancing
ClientとServerの前にHTTP/2対応のリバースプロキシを配置して、背後のサーバーに対して、負荷分散を行う。
Client Side load balancing
Client側でServerの一覧を把握し、request時に負荷分散する。
構成の変更
gRPCの負荷分散を行うためには HTTP/2対応のリバースプロキシ を利用するか、client sideでLBを介さず負荷分散 をする必要があることがわかりました。
変更前の構成

スタディサプリ ENGLISH ではgRPCはすべて内部通信で利用する形になっています。各Serviceはwebやアプリなどが問い合わせる外部apiがあり、そこからInternal ELB(CLB)経由でgRPCを使った内部apiへ問い合わせを行う形です。
上記の構成かつ、Microservicesを取り入れているため、今の段階からすべてのサーバーにClient side load balancingを入れるのは実装側の考慮が多いこと、現在はScalaで統一されていますが、異なる言語を利用した場合にclient側によって、load balacingの内容が統一出来ないことを鑑みて出来るだけproxy側で処理したいことを考慮しました。
Client側にSide Carを用いて、Service Mesh的な構成を取る方法などを考えたのですが、事態が緊急であることと、出来るだけ構成を大きく変えずに効果を出したかったので、今回はInternal ELBとHTTP/2対応のProxyを入れ替えるだけで可能な構成で行いました。
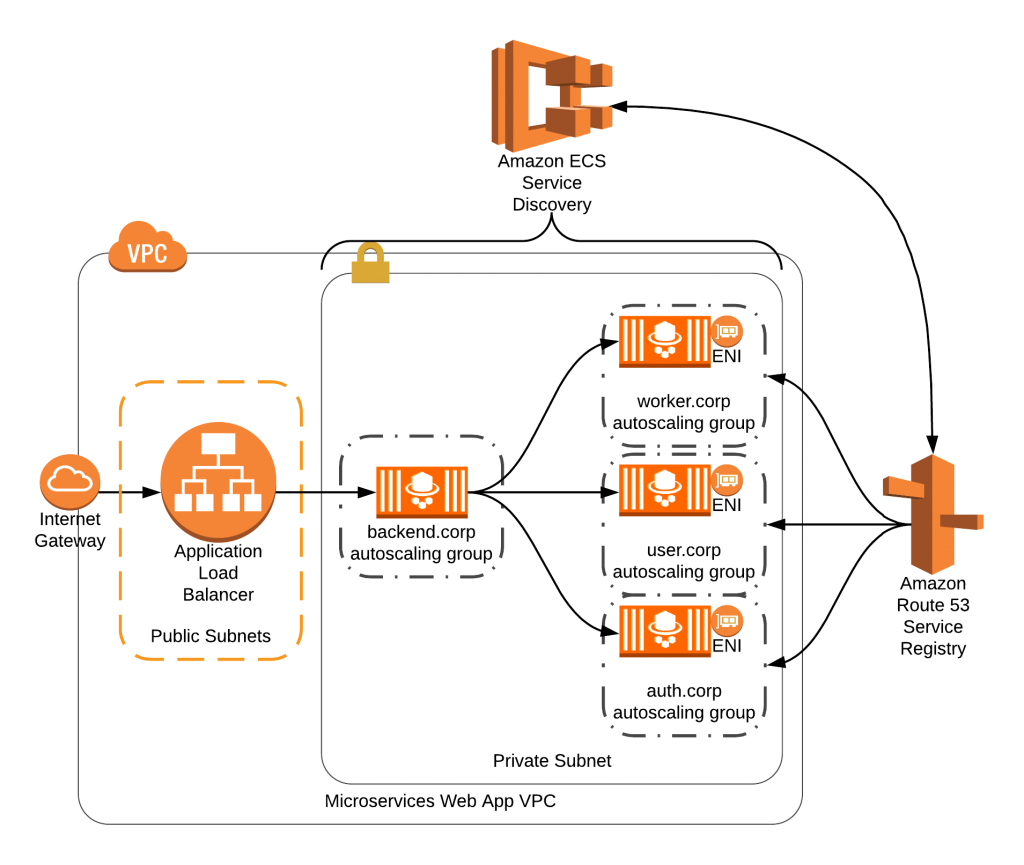
変更後の構成

外部のclientからの通信を受ける部分はELB(ALB)のままで、内部通信のgRPCを受ける部分をHTTP/2対応のProxy(Envoy)に変更し、Proxy自体もECSのTaskとして動かしています。ProxyはgRPCを利用している内部APIのService Discoveryを参照し、負荷分散しています。
Envoy

Serverの前に配置するHTTP/2対応のProxyとしてEnvoyを採用しました。
EnvoyはアメリカでUberと人気を二分するRideshareサービスを運用しているLyftが開発している高機能L4/L7 Proxyです。
採用した理由
- Service Meshで最近話題なIstioのcoreなcomponentの一つであること 4)What is Istio? - envoy
- 現役でLyftという大規模なProductで使われていること
- CNCFにも採択されていて、開発が活発ということ 5)CNCF hosts envoy
- HTTP/2に対応しているだけではなくgRPC用のサポートがたくさん含まれている
- 元々LyftでもELBを使っていたがNetworkの複雑性に耐えられなくなったため開発したProductであること6) Lyft's Envoy: From Monolith to Service Mesh - Matt Klein, Lyft
- Envoyのexample usecaseとしてサーバーの前に配置、LBとして扱うFront Proxyがあったため7)Envoy Front Proxy
- 単純に新しいものを使いたかった
Service Discovery
ELBを使ってロードバランサーを立てる場合は背後に登録するサーバーをマネージドで登録してくれますが、ELBを使わずにロードバランサー立てる場合、ロードバランサーの後ろにサーバーのipを登録する作業を自前で行わないといけません。
その場合、サーバーの変更があった場合に変更した設定ファイルをdeployしなおすか、Service Discoveryのような対象サーバーの一覧を返してくれるサービスを用意 する必要があります。
サーバーの変更があった場合に設定ファイルをdeployしなおす場合、急なscaling outすることが出来なかったり、台数を変更する度にLBのdeployをし直すというのは運用面に難しい部分があるので、Service Discoveryを利用することを検討しました。
Kubernetesの場合は標準でService Discoveryの機能を搭載しており、headless service8)Kubernates headless serviceの説明のような serviceのip一覧を返す機能があります。ですが、私達はECSを利用しており、そのような機能がなく、ConsulなどのService Discoveryの導入も検討していましたが、そのタイミングでAWS ECS Service Discoveryが東京でGAされるという発表があったため9)Amazon ECS Service Discovery がフランクフルト、ロンドン、東京、シドニー、シンガポールの各リージョンで利用可能に、こちらを利用することにしました。
AWS ECS Service Discovery
AWS Service Discoveryはコントロールパネル上は無いものの元々存在していて、Route 53 Auto Naming APIを利用して、特定のhosted zoneに対して自動でdomainを付与し、MULTIVALUE形式で取得出来るというものでした。
今回利用したAWS ECS Service DiscoveryはAWS Service DiscoveryとECSを結びつけるもので、ECSのService上で動くTaskのipの一覧を取得することが出来るDomainを自動で作成することが出来る機能になります。
変更した結果
ELBをEnvoyに変更する前と変更した後の変化です。値はdockerのcpuの使用率を表示しています。
LB変更前

LB変更後

変更前の場合、複数Containerが動いていても、CPUがほぼ使われていないものがあるのが確認できます。一方変更後は、すべてのContainerがほぼ均一に利用されていることが確認出来ると思います。
Envoyの負荷

現在、0.25vCPU/Memory 512MB、冗長化のために2台の構成でEnvoyを立てています。一番アクセス数が多い箇所で平均秒間150〜200ぐらいのリクエストがありますが、CPU使用率2,3パーセントぐらいの負荷で済んでいます。
Envoyを入れたことによる副次的な効果
Envoyは元々LBだけでなく、Microservice間の通信のために作られたService Proxyです。正しく負荷分散を行うために導入したのですが、負荷分散以外にも以下のような効果がありました。
- Envoy側でgRPCのメソッド単位のアクセスログが出せるようになり、ログが追いやすくなった。
- ELBだけでは出来なかったretryやtimeoutなどの細かな設定をLB側に持たせることが出来るようになった。
- Envoy自体にPrometheusのexporter機能がついていて、MetricsをDatadogで取得することでさらなる分析が出来るようになった。
まとめ・余談
- CloudでScale outで対応出来る環境を作成するために負荷分散は重要。出来てないとCloudにお金くべても解決できなくなってしまう。
- Metrics重要。DatadogでMetricsをしっかり取る体制が出来ていたので問題に気づくことが出来た。
- Envoy,gRPCのような使われている数が多く、新しいProductは多くの人の苦労から出来ていて非常に優秀。ただ情報が少ないなどのつらみもある。
- 勉強会とかでも色々聞いてみたが、Web系界隈はあんまりgRPC使っている数はそんなに多くなかった。
- 使っている場合はKubernetes → headless service → client side load balancingというパターンで解決が多い。
今後やっていきたいこと
Kubernetesの導入検討
gRPCの負荷や仕様を調べていく中ではやはりKubernetesのエコシステムを利用した方が良い部分が多かったので、EKSが東京に来たらEKSへの移行も検討してみたいです。
Service Meshの導入検討
今回はEnvoyをLB的な使い方で使いましたが、Envoy自身は、細かい通信の制御や認証、Chaos Engineeringなどに用いられるFault injectionなどかなりたくさんの機能を有しています。Serviceが今後拡大していく中でより障害や変化に強いインフラにしていくためにも検証したいと考えています。
脚注